Termux 高级终端安装使用配置教程, 这篇文章拖了有小半年. 因为网上相关的文章相对来说还是比较少的, 恰好今天又刷了机, 所以就特意来总结一下, 希望本文可以帮助到其他的小伙伴. 发挥 Android 平台更大的 DIY 空间.
Termux是一个Android下一个高级的终端模拟器, 开源且不需要root, 支持apt管理软件包,十分方便安装软件包, 完美支持Python,PHP,Ruby,Go,Nodejs,MySQL等。随着智能设备的普及和性能的不断提升,如今的手机、平板等的硬件标准已达到了初级桌面计算机的硬件标准, 用心去打造完全可以把手机变成一个强大的工具.
Google Play 下载的版本比酷安要新, 有能力建议下载 Google PLay 版本的.
长按屏幕
显示菜单项(包括复制、粘贴、更多),此时屏幕出现可选择的复制光标
长按屏幕
├── COPY:复制
├── PASTE:更多
├── More:更多
├── Select URL: 选择网址
└── Share transcipt: 分享命令脚本
└── Reset: 重置
└── Kill process: 杀掉当前终端会话进程
└── Style: 风格配色
└── Help: 帮助文档
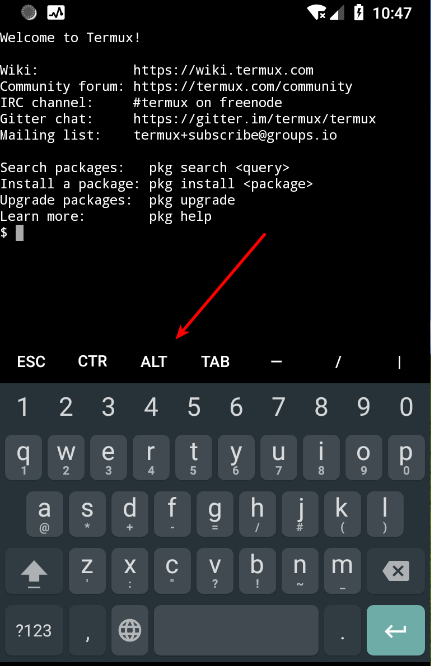
从左向右滑动
显示隐藏式导航栏,可以新建、切换、重命名会话 session 和调用弹出输入法
显示扩展功能按键
扩展功能键是什么? 就是 PC 端常用的按键如: ESC 键,CTR 键,TAB 键, 但是手机上难以操作的一些按键.
效果图
方法一
从左向右滑动, 显示隐藏式导航栏, 长按左下角的KEYBOARD.
方法二
使用Termux快捷键:音量++Q键
Ctrl键是终端用户常用的按键 - 但大多数触摸键盘都没有这个按键。为此,Termux 使用音量减小按钮来模拟Ctrl键。
例如,在触摸键盘上按音量减小+ L发送与在硬件键盘上按Ctrl + L相同的输入。
Ctrl+A -> 将光标移动到行首Ctrl+C -> 中止当前进程Ctrl+D -> 注销终端会话Ctrl+E -> 将光标移动到行尾Ctrl+K -> 从光标删除到行尾Ctrl+L -> 清除终端Ctrl+Z -> 挂起(发送 SIGTSTP 到)当前进程
音量加键也可以作为产生特定输入的特殊键.
音量加+E -> Esc 键音量加+T -> Tab 键音量加+1 -> F1(和音量增加 + 2→F2 等)音量加+0 -> F10音量加+B -> Alt + B,使用 readline 时返回一个单词音量加+F -> Alt + F,使用 readline 时转发一个单词音量加+X -> Alt+X音量加+W -> 向上箭头键音量加+A -> 向左箭头键音量加+S -> 向下箭头键音量加+D -> 向右箭头键音量加+L -> | (管道字符)音量加+H -> 〜(波浪号字符)音量加+U -> _ (下划线字符)音量加+P -> 上一页音量加+N -> 下一页音量加+. -> Ctrl + \(SIGQUIT)音量加+V -> 显示音量控制音量加+Q -> 显示额外的按键视图
Termux除了支持apt命令外, 还在此基础上封装了pkg命令,pkg命令向下兼容apt命令.apt命令大家应该都比较熟悉了, 这里直接简单的介绍下pkg命令:
Bash
pkg search <query> 搜索包
pkg install <package> 安装包
pkg uninstall <package> 卸载包
pkg reinstall <package> 重新安装包
pkg update 更新源
pkg upgrade 升级软件包
pkg list-all 列出可供安装的所有包
pkg list-installed 列出已经安装的包
pkg shoe <package> 显示某个包的详细信息
pkg files <package> 显示某个包的相关文件夹路径
Bash
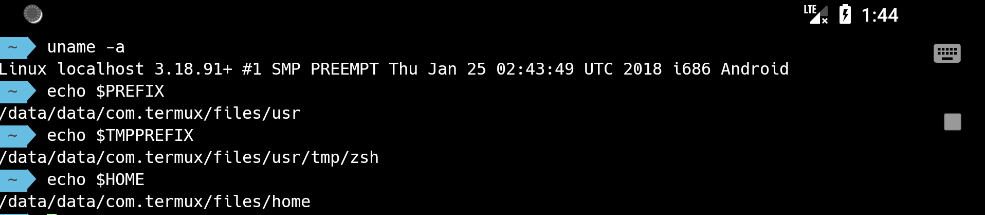
~ > echo $HOME
/data/data/com.termux/files/home
~ > echo $PREFIX
/data/data/com.termux/files/usr
~ > echo $TMPPREFIX
/data/data/com.termux/files/usr/tmp/zsh
长期使用 Linux 的朋友可能会发现,这个 HOME 路径看上去可能不太一样, 为了方便,Termux 提供了一个特殊的环境变量:PREFIX
更换Termux清华大学源, 加快软件包下载速度.
设置默认编辑器
编辑源文件
将原来的https://termux.net官方源替换为http://mirrors.tuna.tsinghua.edu.cn/termux
Bash
export EDITOR=vi
直接编辑源文件
上面是官方推荐的方法, 其实还有更简单的方法, 类似于 Linux 下直接去编辑源文件:
Bash
apt edit-sources
如果清华源 出一些问题的话,大家可以尝试先用着官方源:
Bash
# The termux repository mirror from TUNA:
deb https://mirrors.tuna.tsinghua.edu.cn/termux stable main保存并退出
Bash
vi $PREFIX/etc/apt/sources.list
终端配色
主要使用了zsh来替代bash作为默认shell.
使用一键安装脚本来安装, 一步到位, 顺便启动了外置存储, 可以直接访问 SD 卡下的目录.
执行下面这个命令确保已经安装好了 curl
Bash
# The main termux repository:
deb https://termux.org/packages/ stable main
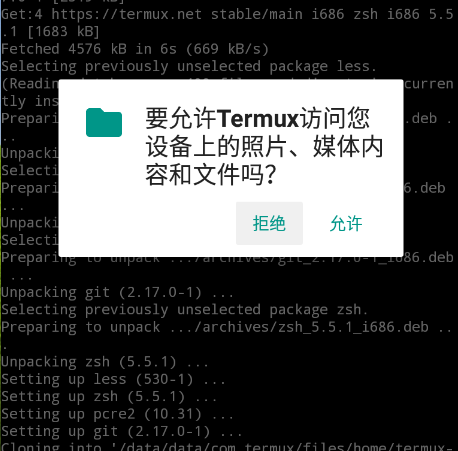
Android6.0 以上会弹框确认是否授权,
允许
授权后
Termux
可以方便的访问 SD 卡文件.
脚本允许后先后有如下两个选项:
pkg update
pkg install vim curl wget git unzip unrar
分别选择背景色和字体
想要继续更改挑选配色的话, 继续运行脚本来再次筛选:
Bash
sh -c "$(curl -fsSL https://github.com/Cabbagec/termux-ohmyzsh/raw/master/install.sh)"
exit重启sessions会话生效配置
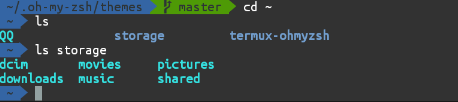
访问外置存储优化
执行过上面的zsh一键配置脚本后, 并且授予文件访问权限的话, 会在家目录生成storage目录,并且生成若干目录,软连接都指向外置存储卡的相应目录
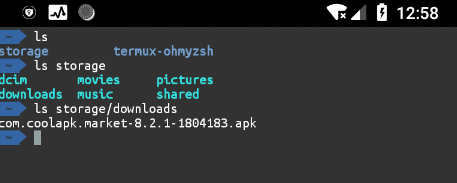
创建 QQ 文件夹软连接
手机上一般经常使用手机 QQ 来接收文件, 这里为了方便文件传输, 直接在storage目录下创建软链接.
QQ
Bash
Enter a number, leave blank to not to change: 14
Enter a number, leave blank to not to change: 6
TIM
Bash
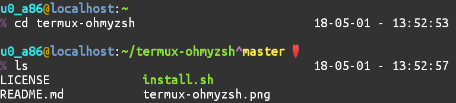
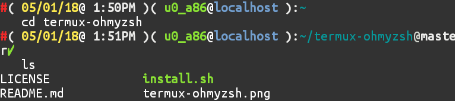
$ ~/termux-ohmyzsh/install.sh
最后效果图如下:

这样可以直接在
home
目录下去访问 QQ 文件夹, 非常方便文件的传输, 大大提升了工作效率.
http://mirrors.tuna.tsinghua.edu.cn/termux
oh my zsh 主题配色
编辑.zshrc配置文件
第一行可以看到, 默认的主题是agnoster主题:

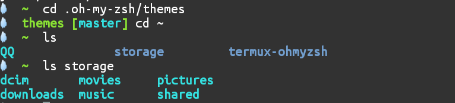
在
.oh-my-zsh/themes
目录下放着
oh-my-zsh
所有的主题配置文件.
下面是国光认为还不错的几款主题
agnoster
robbyrussell

jaischeema

re5et
junkfood
cloud
random
当然如果你是个变态的话, 可以尝试random主题, 每打开一个会话配色主题都是随机的.
修改启动问候语
默认的启动问候语如下:
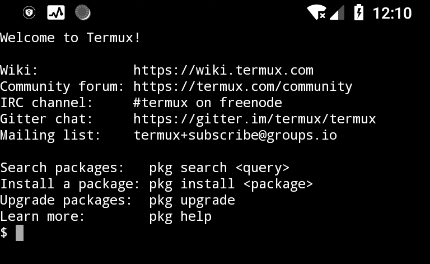
这个对于初学者有一定的帮助在前期, 随着对
Termux
的熟悉, 这个默认的问候语就会显得比较臃肿.
编辑问候语文件直接修改问候语:
修改完的效果如下:
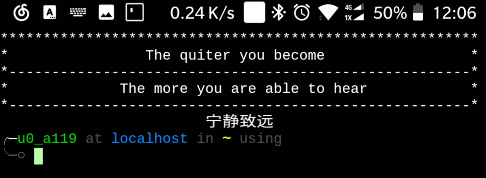
这样启动新的会话的时候看上去就会简洁很多.
手机没有 root
利用proot工具来模拟某些需要 root 的环境
然后终端下面输入:
即可模拟root环境
在这个proot环境下面, 相当于是进入了home目录, 可以很方便地进行一些配置.
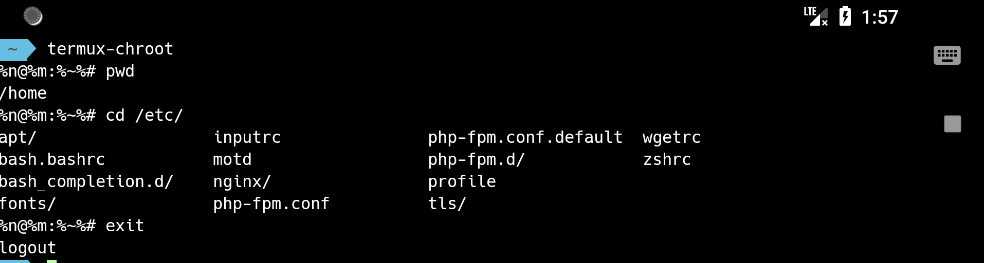
在管理员身份下,输入
exit
可回到普通用户身份。
手机已经 root
安装tsu, 这是一个su的 termux 版本, 用来在 termux 上替代su:
然后终端下面输入:
即可切换root用户, 这个时候会弹出root授权提示, 给予其root权限, 效果图如下:
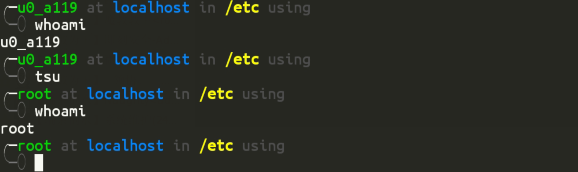
在管理员身份下,输入
exit
可回到普通用户身份。
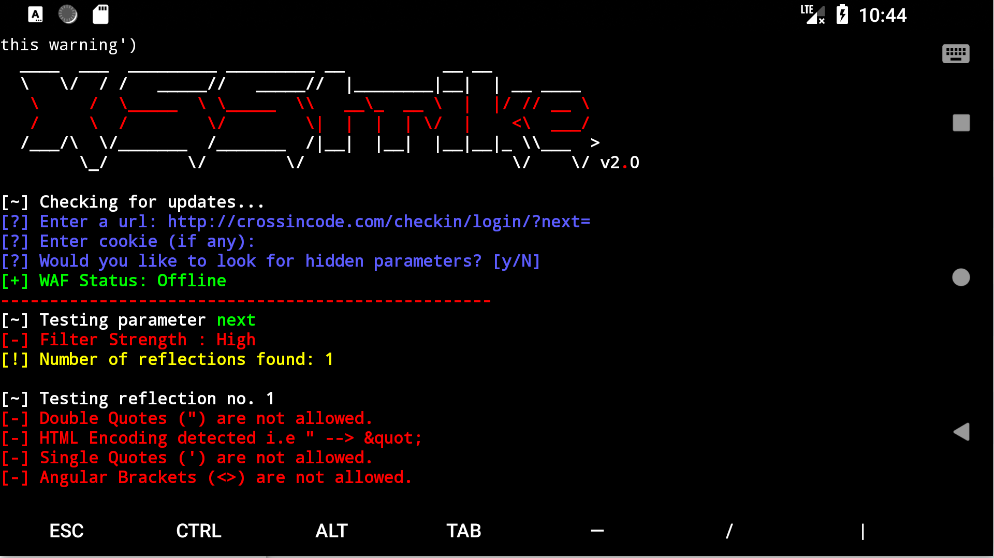
因为termux可以很好的支持Python, 所以几乎所有用Python编写的安全工具都是可以完美的运行使用的. 总的来说可玩性还是比较高的.
安装Metasploit
Termux 官方提供的自动话脚本安装方法如下:
ln -s /data/data/com.termux/files/home/storage/shared/tencent/QQfile_recv QQ
注 在 x86 平台下自动化安装失败,想在 x86 平台下安装的参考 官方的文档 手动去安装.
这个过程平均耗时大约 3 分钟左右(使用国内的清华源的情况下).
配置 msf 数据库缓存
意外发现数据库居然都配置好了,启动msfconsole会自动连接数据库了.
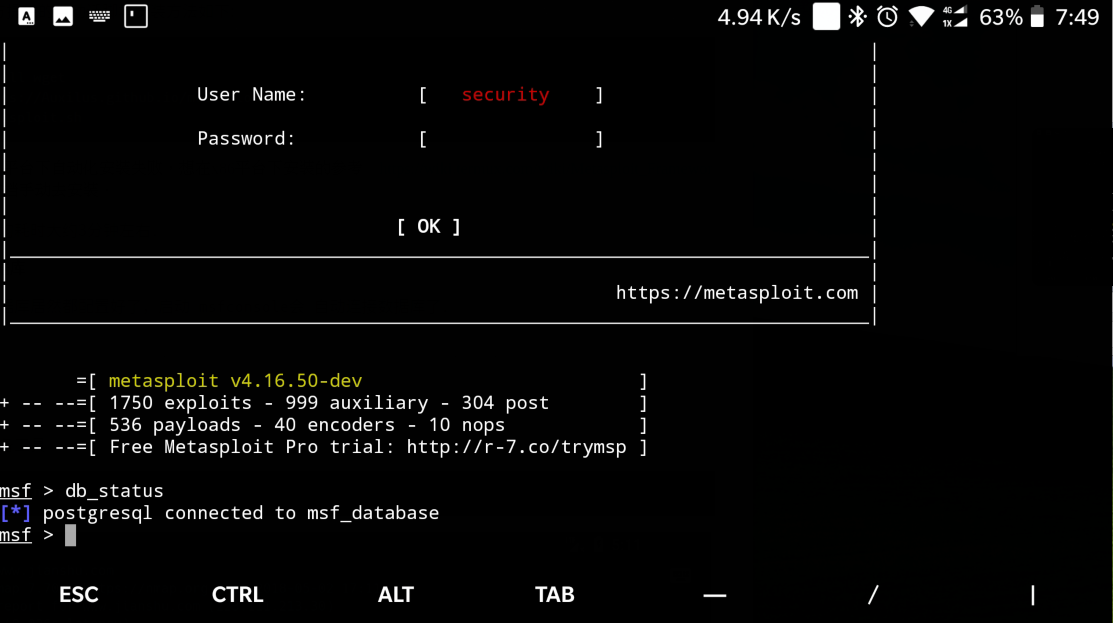
接下来重建数据库缓存
这个时候立刻去搜索发现缓存依然没有建立,只能使用慢速搜索,这里其实是这个缓存建立需要时间,只要稍微等待一下就可以了.
国光以前这里做过测试,缓存建立的平均时间是 3 分钟左右.
然后就可以实现msf秒搜索的效果了,无需等待,感觉比电脑上还要快呐
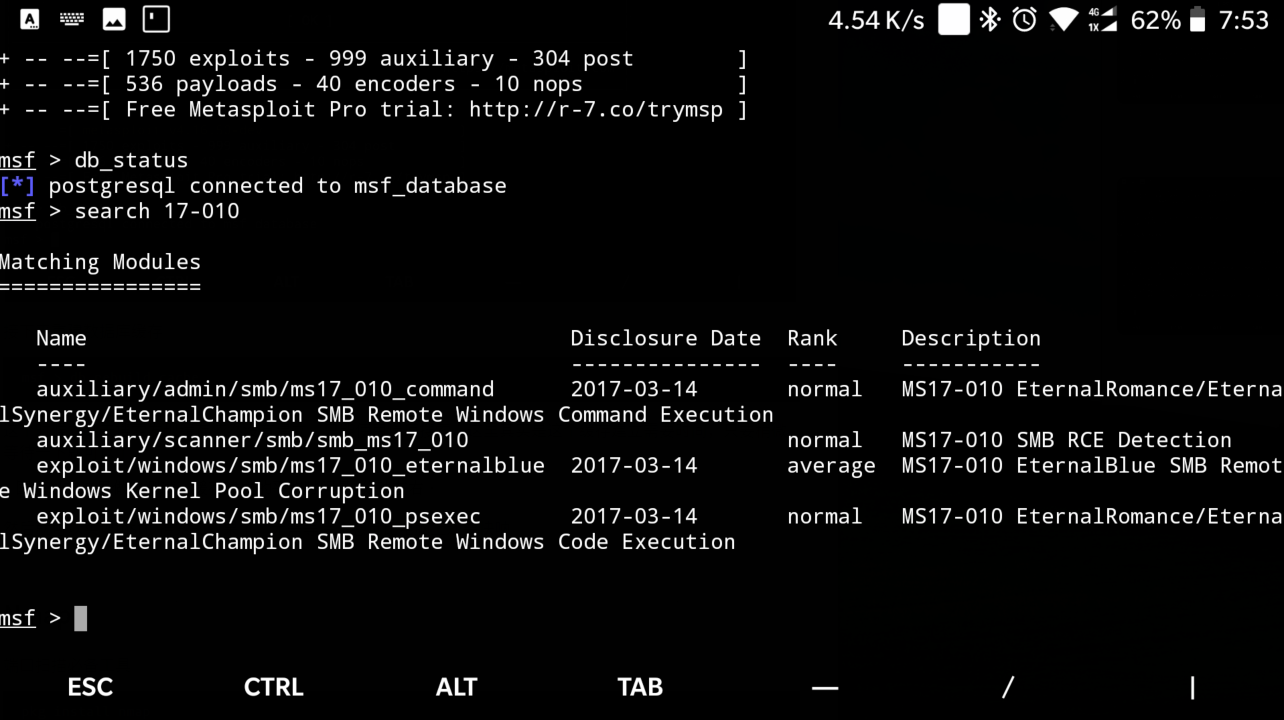
使用自动化脚本安装好Metasploit后使用db_status发现数据库是处于连接状态的, 然后在使用db_rebuild_cache重新建立缓存, 等待大约 3 分钟后, 便可以使用快速搜索了, 没毛病~
但是
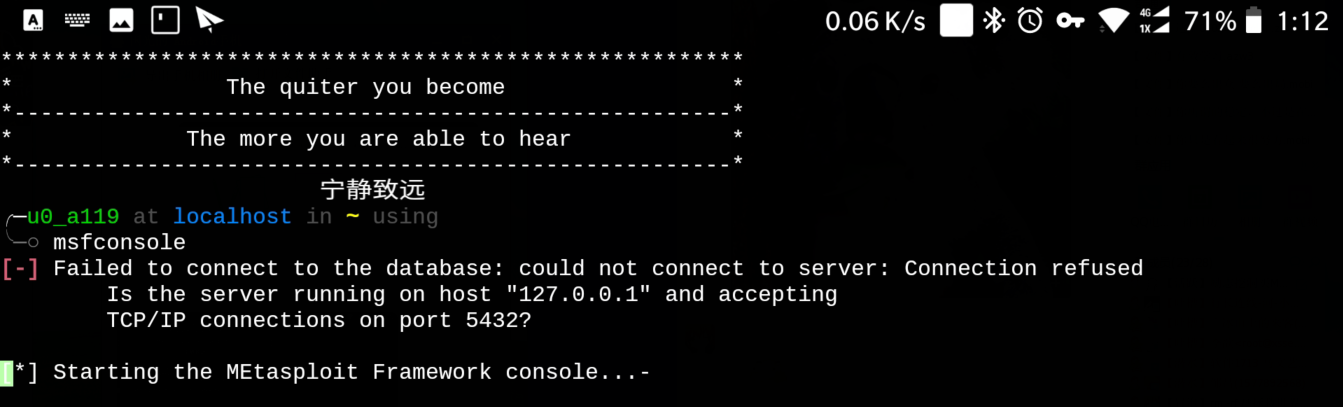
在一段日子过后, 可能会出现以下情况:
Bash
ln -s /data/data/com.termux/files/home/storage/shared/tencent/TIMfile_recv TIM
报这个错误是因为postgresql数据库没有启动造成的. 解决方法就是启动数据库:
本方法只针对 termux 上使用自动化脚本安装 msf
Bash
$ vim .zshrc
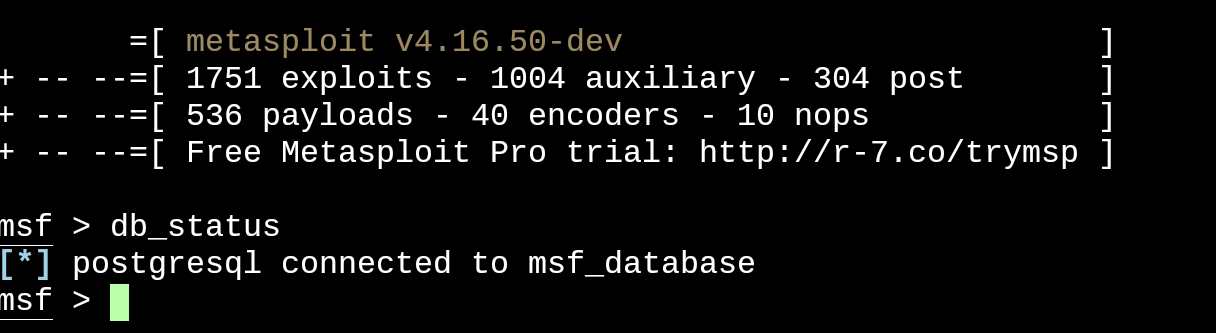
启动数据库后重新进入msfconsole会发现启动没有报错了,db_status查看下数据库连接, 也正常了:
Nmap
端口扫描必备工具
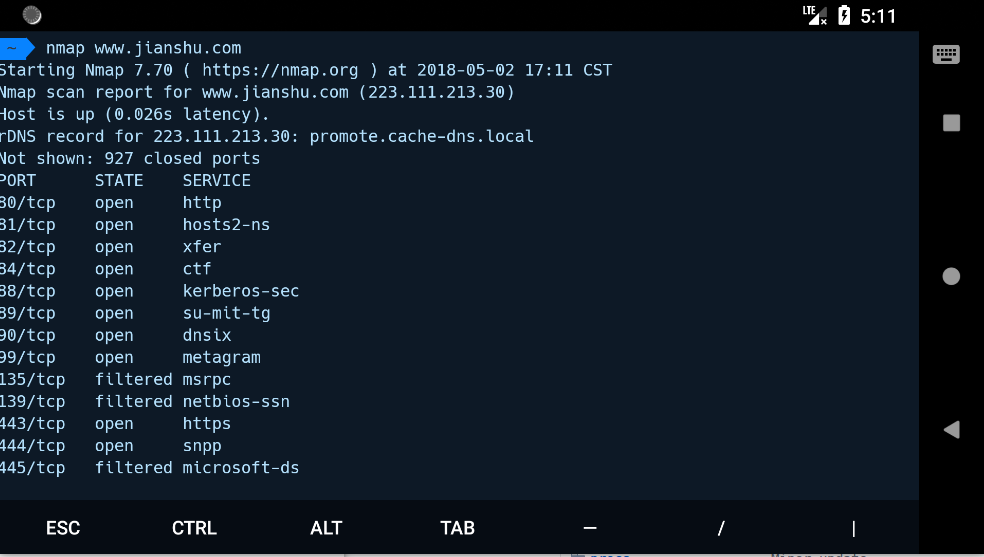
hydra
Hydra 是著名的黑客组织 THC 的一款开源暴力破解工具这是一个验证性质的工具,主要目的是:展示安全研究人员从远程获取一个系统认证权限。
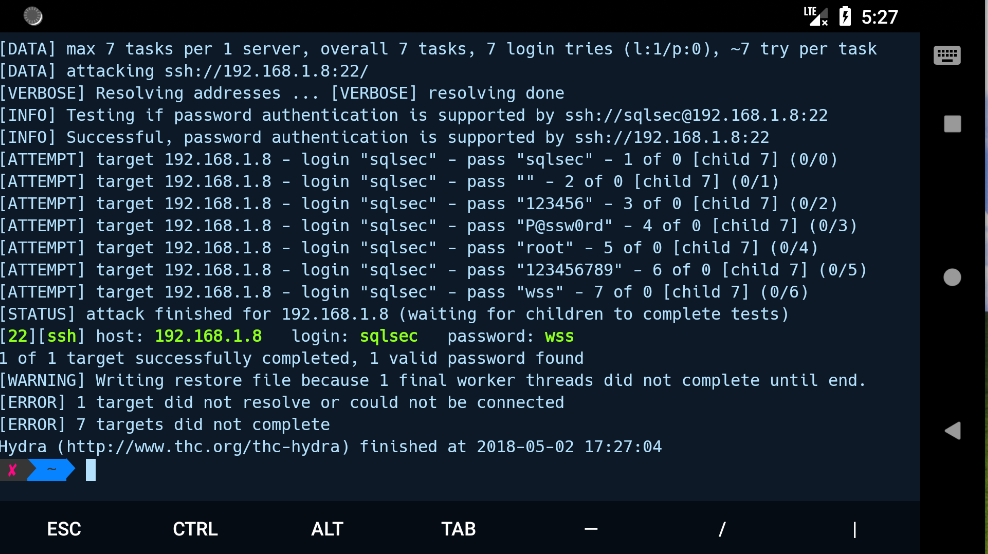
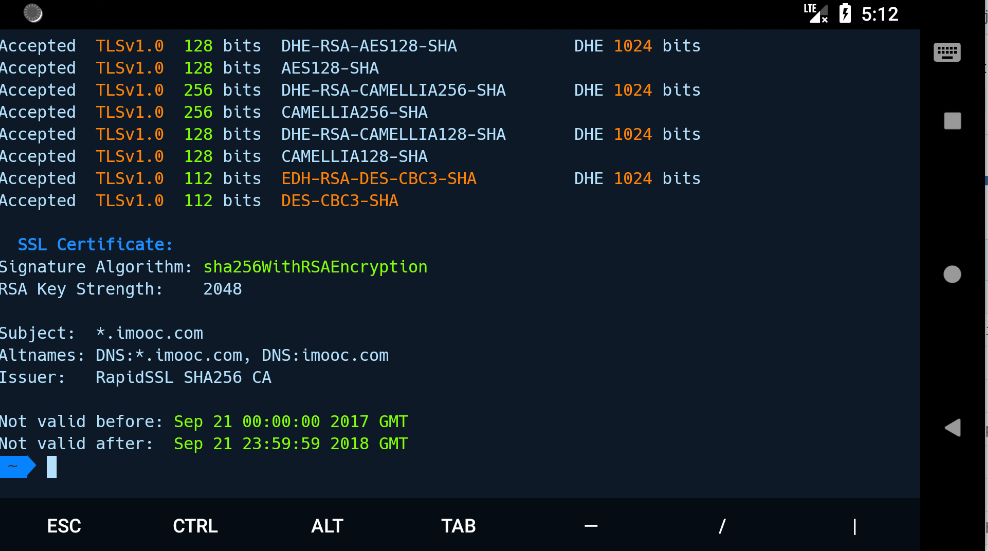
sslscan
SSLscan 主要探测基于 ssl 的服务,如 https。SSLscan 是一款探测目标服务器所支持的 SSL 加密算法工具。
SSlscan 的代码托管在 Github
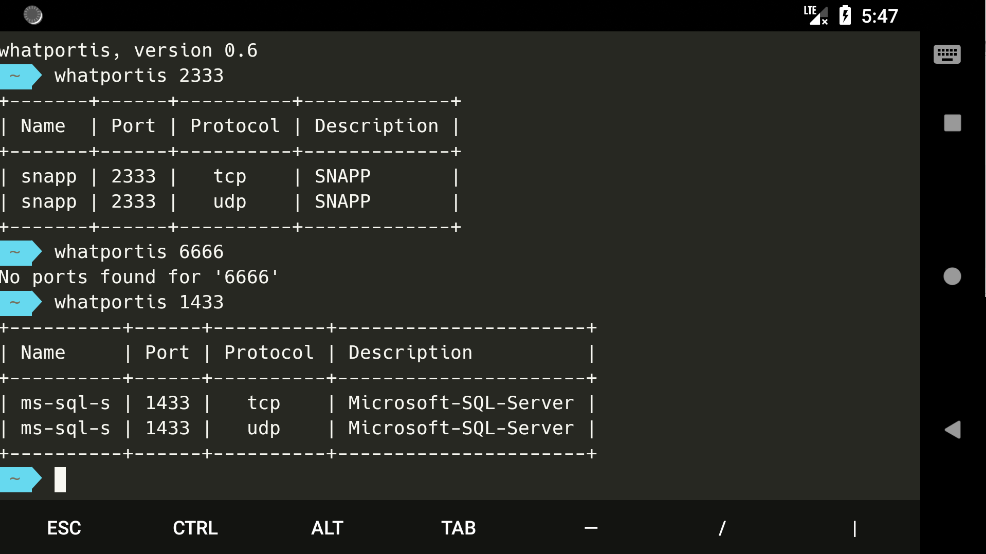
whatportis
whatportis 是一款可以通过服务查询默认端口,或者是通过端口查询默认服务的工具,简单易用。在渗透测试过程中,如果需要查询某个端口绑定什么服务器,或者某个应用绑定的默认端口,可以使用 whatportis 查询。
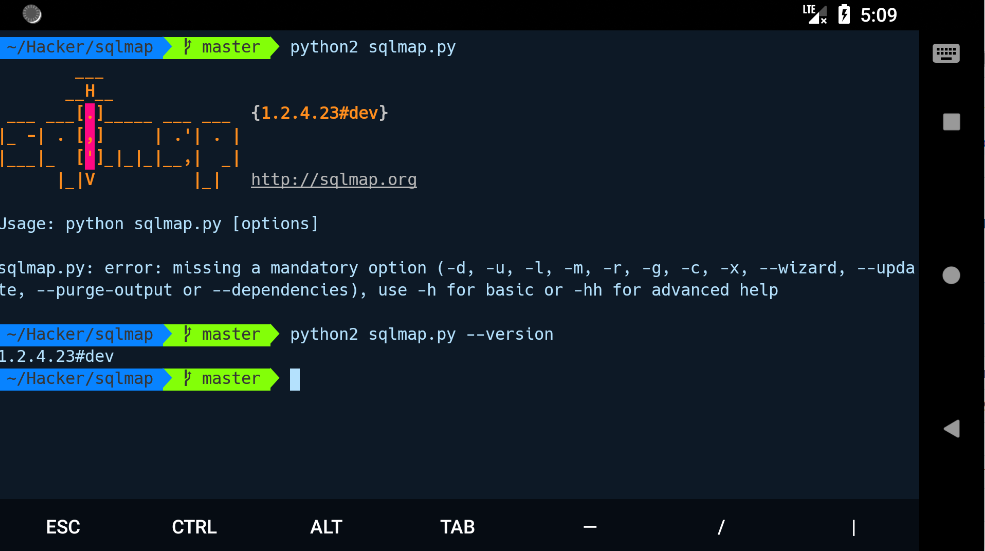
SQLmap
SQLmap 是一款用来检测与利用 SQL 注入漏洞的免费开源工具 官方项目地址
直接git clone源码
ZSH_THEME="random"
sqlmap 支持 pip 安装了, 所以建议直接 pip install sqlmap 来进行安装, 然后终端下直接 sqlmap 就可以了, 十分方便.
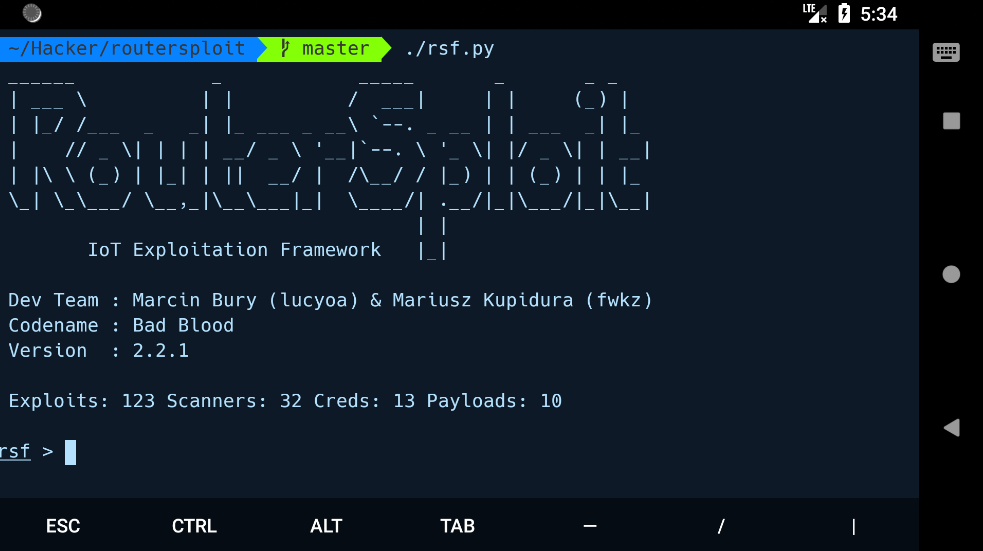
RouterSploit
RouteSploit 框架是一款开源的路由器等嵌入式设备漏洞检测及利用框架。
Bash
vim $PREFIX/etc/motd
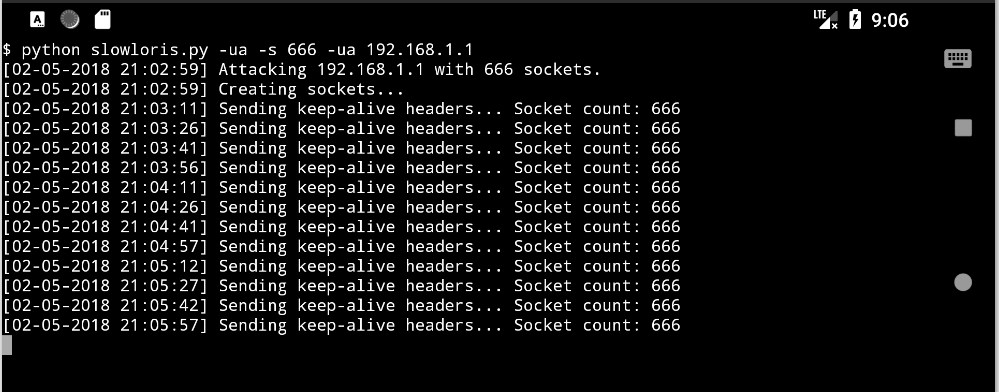
Slowloris
低带宽的 DoS 工具
pkg install proot
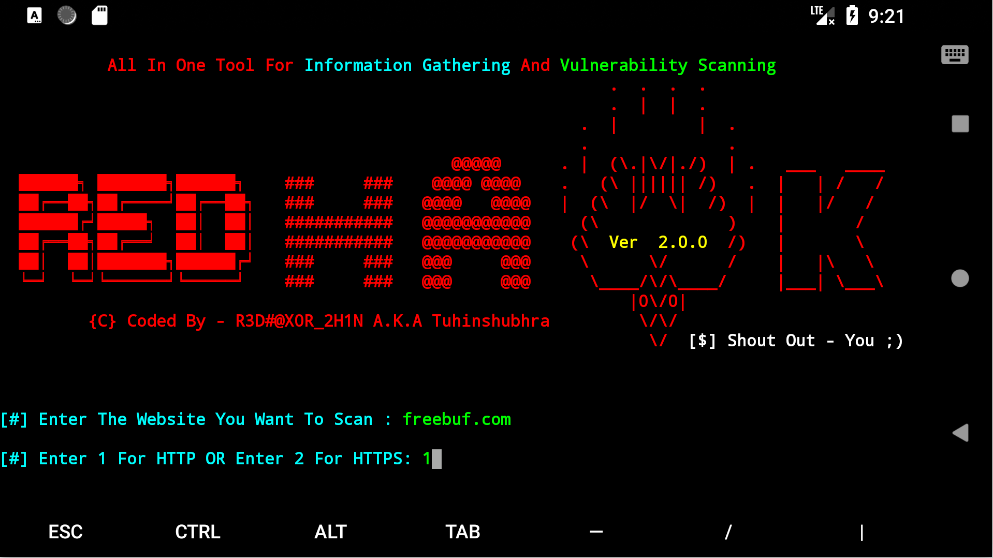
RED_HAWK
一款采用 PHP 语言开发的多合一型渗透测试工具,它可以帮助我们完成信息采集、SQL 漏洞扫描和资源爬取等任务。
Bash
termux-chroot
Cupp
Cupp 是一款用 Python 语言写成的可交互性的字典生成脚本。尤其适合社会工程学,当你收集到目标的具体信息后,你就可以通过这个工具来智能化生成关于目标的字典。
pkg install tsu
Hash-Buster
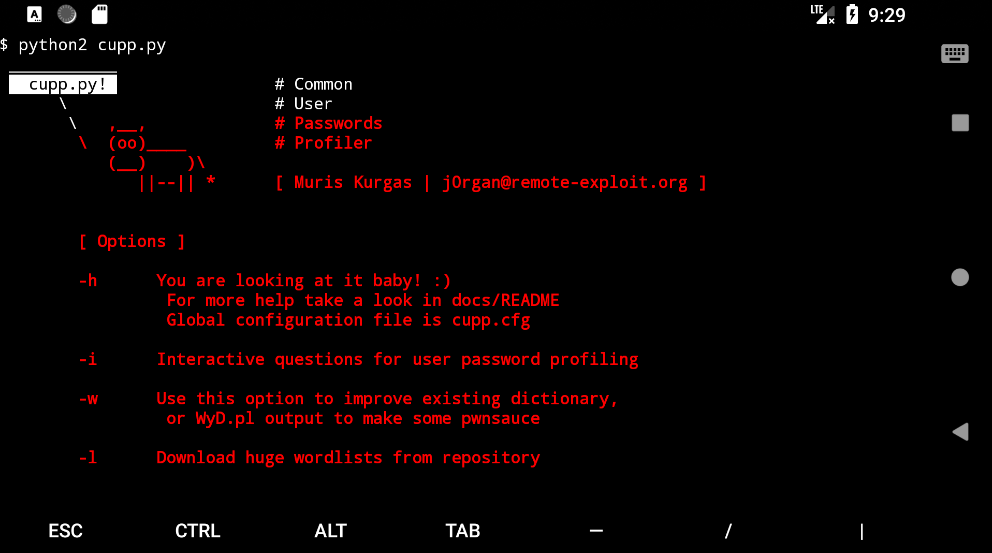
Hash Buster 是一个用 python 编写的在线破解 Hash 的脚本,官方说 5 秒内破解, 速度实际测试还不错哦~
tsu
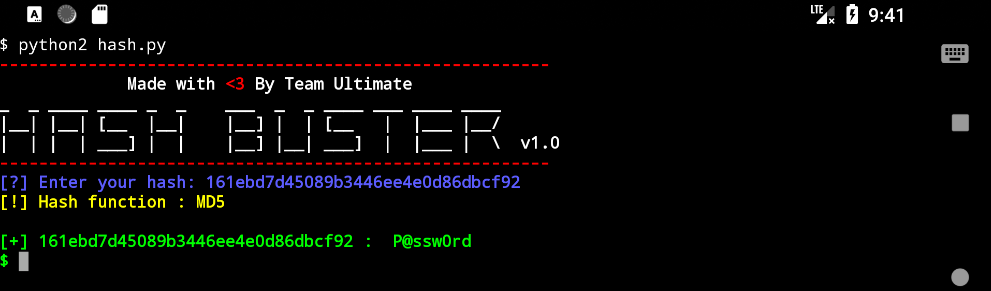
D-TECT
D-TECT 是一个用 Python 编写的先进的渗透测试工具,
- wordpress 用户名枚举
- 敏感文件检测
- 子域名爆破
- 端口扫描
- Wordperss 扫描
- XSS 扫描
- SQL 注入扫描等
cd ~
pkg install wget
wget https://Auxilus.github.io/metasploit.sh
bash metasploit.sh
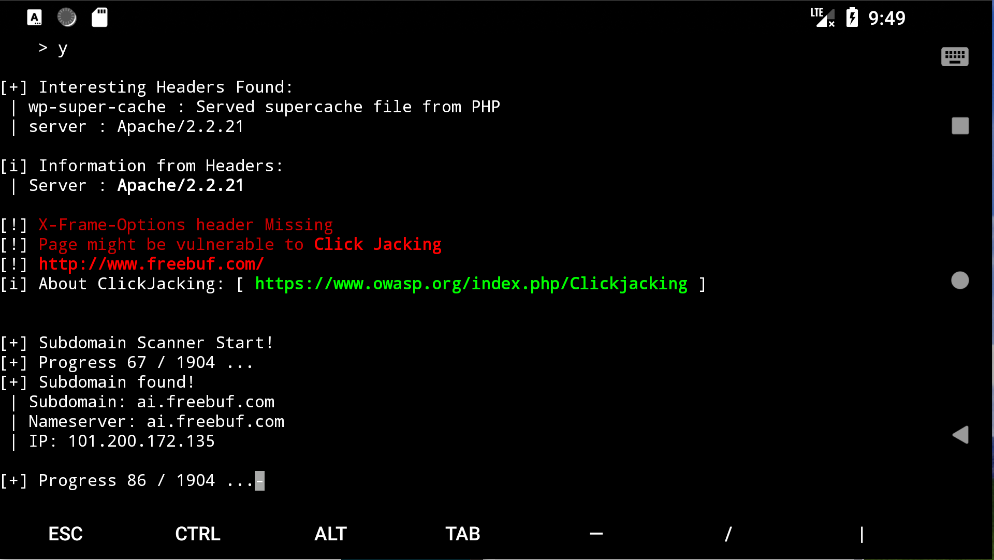
WPSeku
WPSeku 是一个用 Python 写的简单的 WordPress 漏洞扫描器,它可以被用来扫描本地以及远程安装的 WordPress 来找出安全问题。被评为 2017 年最受欢迎的十大开源黑客工具.
Bash
msf > db_rebuild_cache
XSStrike
XSStrike 是一种先进的 XSS 检测工具。它具有强大的模糊测试引擎.
Bash
msfconsole
[-] Failed to connect to the database: could not connect to server: Connection refused
Is the server running on host "127.0.0.1" and accepting
TCP/IP connections on port 5432?
小结
因为 Termux 完美的支持Python和Perl等语言, 所以有太多优秀的信息安全工具值得大家去发现了, 这里我就不一一列举了.
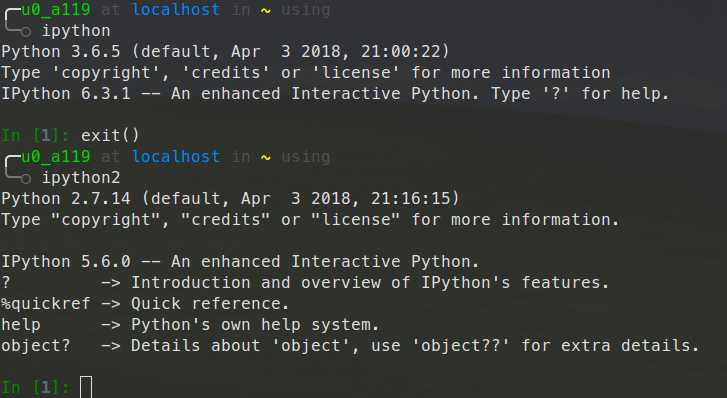
安装 python2.7
安装完成后, 使用python2命令启动python 2.7.14环境.

安装 python3
安装完成后, 使用python命令启动python 3.6.5环境.

升级 pip 版本
Bash
pg_ctl -D $PREFIX/var/lib/postgresql start
这两条命令分别升级了pip2和pip3到最新版.
pip 版本查看

ipython
ipython 是一个 python 的交互式 shell,支持变量自动补全,自动缩进,支持 bash shell 命令,内置了许多很有用的功能和函数。学习 ipython 将会让我们以一种更高的效率来使用 python。
先安装clang, 否则直接使用pip安装ipython会失败报错.
pkg install nmap
然后分别使用ipython和ipython2进入py2和py3控制台:
编辑器
终端下有vim神器, 并且官方也已经封装了vim-python, 对vim进行了 Python 相关的优化.
Bash
pkg install hydra
解决 termux 下的 vim 汉字乱码
在家目录下, 新建.vimrc文件
添加内容如下:
pkg install sslscan
然后source下变量:
效果图
安装 nodejs
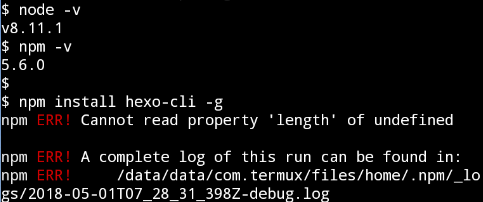
安装比较方便, 但是在安装的时候报错了
pip2 install whatportis
查了下是这边版本的问题
官方的解决方法如下
disable concurrency in case of libuv/libuv#1459
解决 npm 安装报错
Bash
git clone https://github.com/sqlmapproject/sqlmap.git
cd sqlmap
python2 sqlmap.py
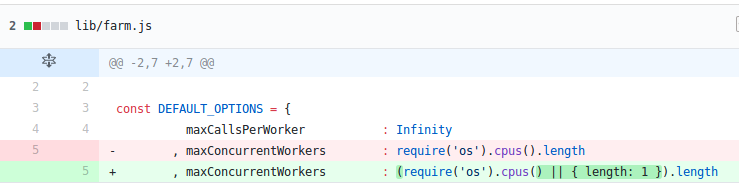
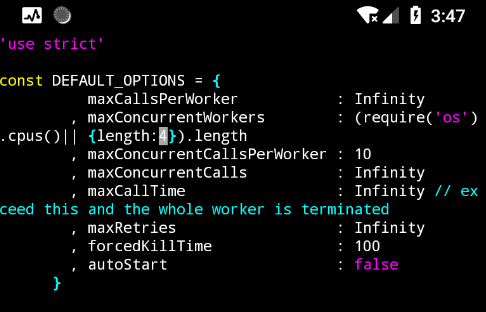
我这里修改 length 的是4, 这个好像和 CPU 有关, 总之这里的 length 得指定一个数字.
然后在重新安装下
npm install hexo-cli -g
成功.
MariaDB 数据库管理系统是 MySQL 的一个分支,主要由开源社区在维护,采用 GPL 授权许可。开发这个分支的原因之一是:甲骨文公司收购了 MySQL 后,有将 MySQL 闭源的潜在风险,因此社区采用分支的方式来避开这个风险。
安装 mariadb
安装基本数据
启动 mariadb 服务
启动完成后, 这个会话就一直存活, 类似与 debug 调试一样, 只有新建会话才可以操作.
关于隐藏会话可以使用
nohup
命令和
tmux
命令, 这里我建议使用
tmux
命令
新建 termux 会话
由于 mariadb 安装的时候没有设置密码, 当前的mariadb密码为空.
直接进入mariadb数据库. 输入exit退出数据库.
修改密码
输入一下命令, 进行密码相关的安全设置:
Bash
pip2 install requests
git clone https://github.com/reverse-shell/routersploit
cd routersploit
python2 rsf.py
输入当前输入密码
因为是空密码, 这里默认 回车
Bash
git clone https://github.com/gkbrk/slowloris.git
cd slowloris
chmod +x slowloris.py
设置新密码
这里设置新的 root 密码
Bash
pkg install php
git clone https://github.com/Tuhinshubhra/RED_HAWK.git
cd RED_HAWK
php rhawk.php
其他设置
下面根据个人偏好来进行设置, 没有绝对的要求
Bash
git clone https://github.com/Mebus/cupp.git
cd cupp
python2 cupp.py
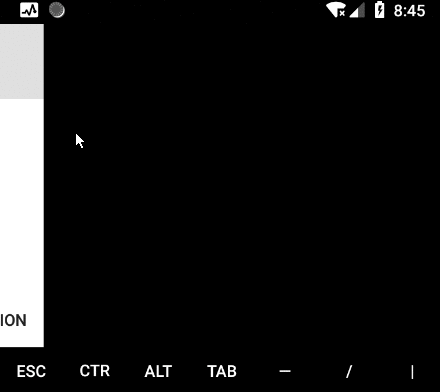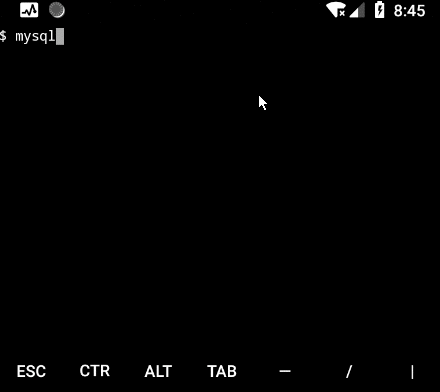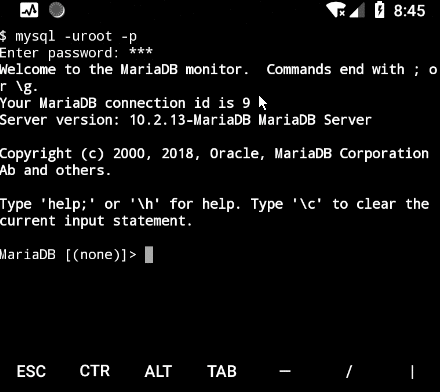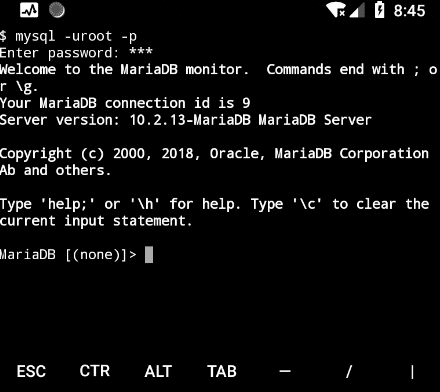
使用密码登录数据库
Mysql
git clone https://github.com/UltimateHackers/Hash-Buster.git
cd Hash-Buster
python2 hash.py
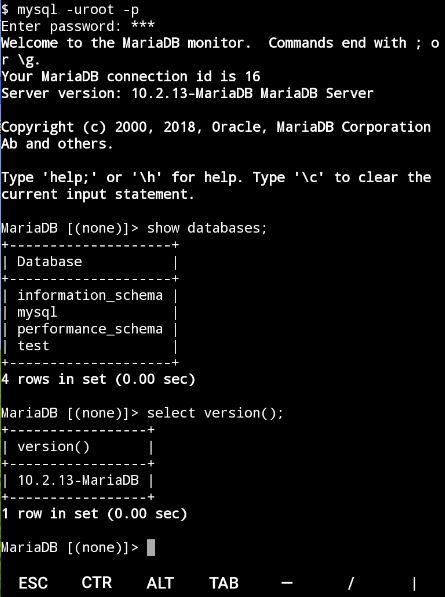
Tmux 是一个优秀的终端复用软件,类似 GNU Screen,但来自于 OpenBSD,采用 BSD 授权。一旦你熟悉了 tmux 后, 它就像一个加速器一样加速你的工作效率。
安装 tmux
新建 mysql 会话
上面介绍的mysqld后会一直卡在那里, 强迫症表示接受不了,重启手机, 现在尝试使用tmux来管理会话.
可以看到最下面的提示, 表明现在是在mysql的会话下面操作
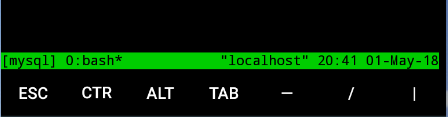
启动 mysqld 并断开会话
启动 mysqld
让会话后台运行
使用快捷键组合Ctrl+b + d,三次按键就可以断开当前会话。
使用 mysql
现在那个mysqld会话被放在后台运行了, 整个界面看上去很简介, 使用
可以优雅的使用数据库了.
效果图
关于
tmux
更多进阶的用法这里不在过多介绍了.
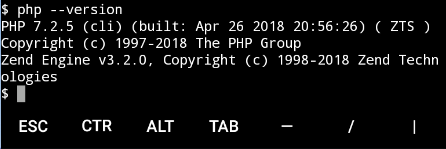
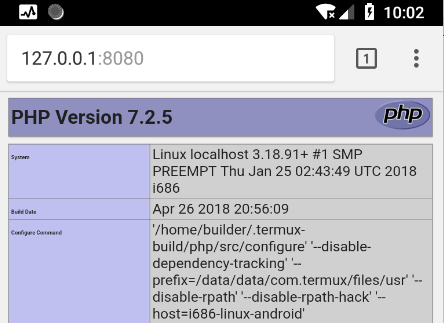
termux封装的 php 版本是php 7.2.5
安装 PHP
查看下版本
自PHP5.4之后 PHP 内置了一个 Web 服务器, 来在termux下尝试下 PHP Web Server 的简单使.
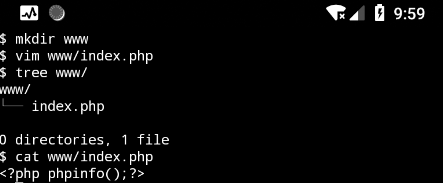
编写测试文件
在家目录下建一个www文件夹:mkdir www
在www文件夹下新建一个index.php文件, 其内容为
启动 WebServer
git clone https://github.com/shawarkhanethicalhacker/D-TECT.git
cd D-TECT
python2 d-tect.py
浏览器访问效果如下:
Nginx 是一个高性能的 Web 和反向代理服务器, 它具有有很多非常优越的特性.
安装 nginx 包
切换 root 用户
尝试下能不能解析默认的index.html主页
这个文件在termux上的默认位置为/data/data/com.termux/files/usr/share/nginx/html/index.html
切换 root 用户
默认的普通权限无法启动 nginx, 需要模拟root权限才可以
没有这个命令的话, 手动安装pkg install proot包
进入模拟的 root 环境
启动 nginx
在模拟的 root 环境下启动nginx
termux上nginx默认的端口是8080
查看下8080端口是否在运行
Bash
git clone https://github.com/m4ll0k/WPSeku.git
cd WPSeku
pip3 install -r requirements.txt
python3 wpseku.py

然后手机本地直接访问:
http://127.0.0.1:8080
查看下
nginx
是否正常启动.
效果图
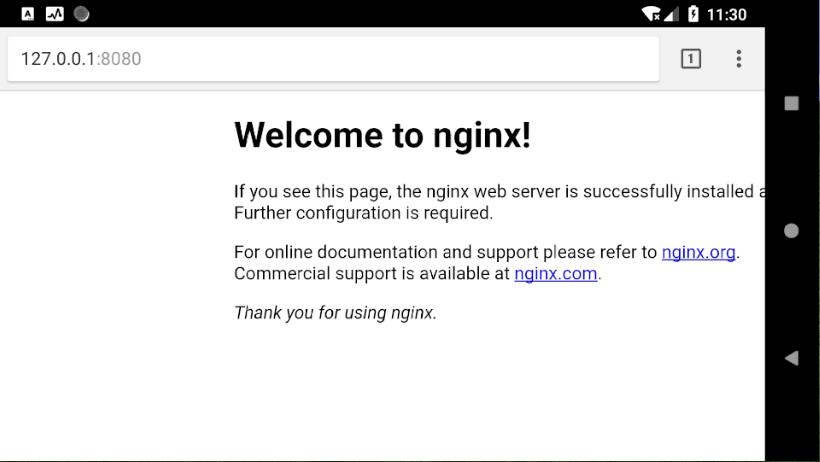
这样一个默认的
nginx
服务就起来了, 但是意义不大, 得配置一下可以解析
php
才会有更大的意义.
停止 nginx 服务
这里是直接杀掉占用端口的进程, 具体端口以实际情况为准.
重启 nginx 服务
nginx解析PHP这里单独拿出一级标题来叙述, 成功解析的话, 下面安装wordpress等 cms 就会轻松很多.
nginx 本身不能处理 PHP,它只是个 web 服务器,当接收到 php 请求后发给 php 解释器处理, nginx 一般是把请求发 fastcgi 管理进程处理, PHP-FPM 是一个 PHP FastCGI 管理器, 所以这里得先安装php-fpm.
这里默已经安装了 nginx 和 php, 没有安装的话, 使用pkg install php nginx来进行安装, 参考上面部分进行配置
安装并配置 php-fpm
安装 php-fpm
配置 php-fpm
进入proot环境, 然后编辑配置文件www.conf(先进 proot 可以更方便操作编写相关配置文件)
Bash
git clone https://github.com/UltimateHackers/XSStrike.git
cd XSStrike
pip2 install -r requirements.txt
python2 xsstrike
定位搜索listen找到
pkg install python2
将其改为
配置 nginx
在proot环境下, 然后编辑配置文件nginx.conf
pkg install python
下面给出已经配置好的模板文件, 直接编辑替换整个文件即可:
Bash
python2 -m pip install --upgrade pip
python -m pip install --upgrade pip
里面的网站默认路径就是nginx默认的网站根目录:
Bash
pkg install clang
pip install ipython
pip3.6 install ipython
要修改网站默认路径的话, 只需要修改这两处即可.
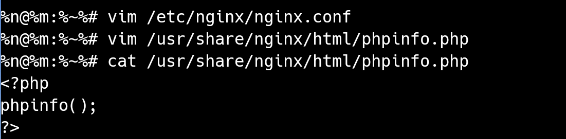
建立 php 测试文件
在/usr/share/nginx/html目录下新建一个phpinfo.php文件, 其内容是:<?php phpinfo();?>
went
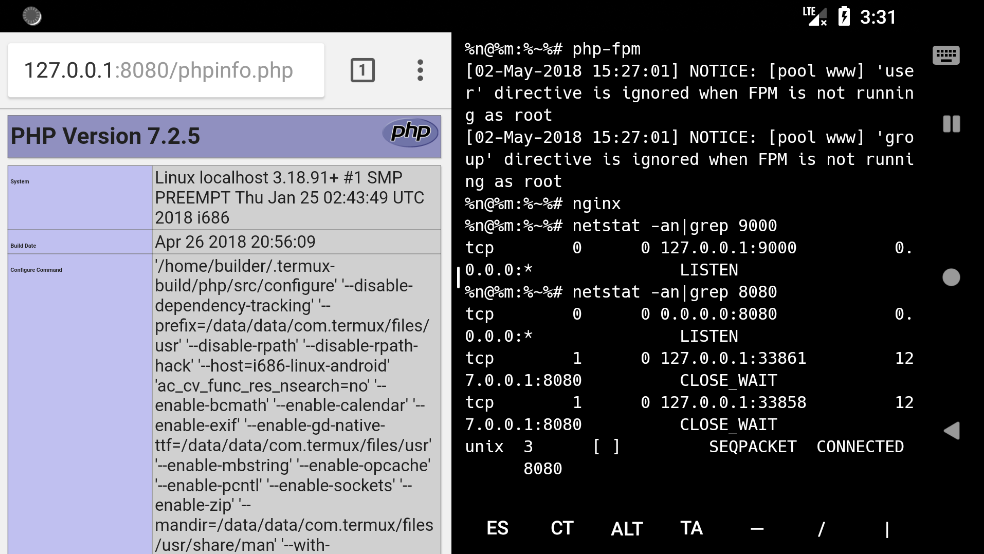
启动 php-fpm 和 nginx
在proot环境下面分别启动php-fpm和nginx, 这里的nginx不在proot环境下启动后会出一些问题, 感兴趣的可以自己去研究看看.
浏览器访问测试
浏览器访问http://127.0.0.1:8080/phpinfo.php 查询php文件是否解析了.
这里只是用wordpress做个典型安利来讲解, 类似地可以安装Discuz,DeDecms等国内主流的 PHP 应用程序.
方法一 使用 PHP 内置的 Web Server
确保安装并配置了php和mariadb, 没有安装好的话, 参考本文中具体细节部分来进行安装.
新建数据库
*** 这里是 mysql 的密码
Sql
pkg install vim-python
下载解压 wordpress
Bash
vim .vimrc
启动 PHP Web Server
到解压后的wordpress目录下, 执行
Bash
set fileencodings=utf-8,gb2312,gb18030,gbk,ucs-bom,cp936,latin1
set enc=utf8
set fencs=utf8,gbk,gb2312,gb18030
然后浏览器访问127.0.0.1:8080开始进行wordperss的安装.
效果图
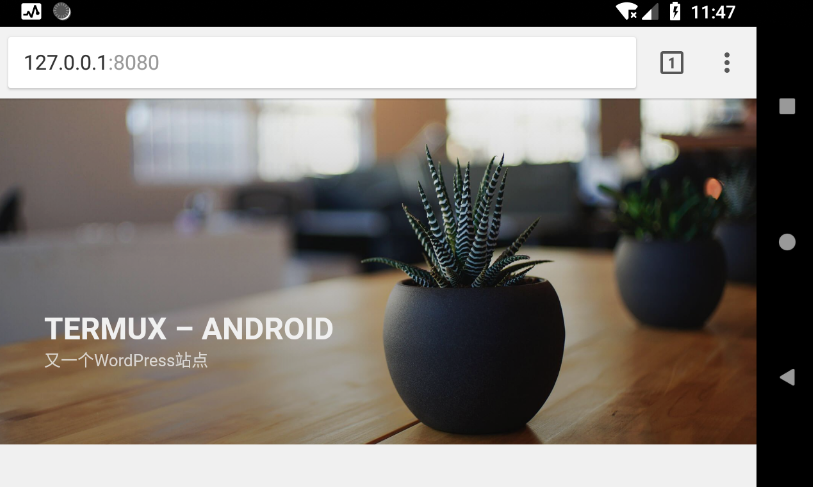
方法二 nginx+PHP+Mariadb
上面使用的方法一是直接使用 PHP 自带的PHP Web Server来运行的, 看上去不够严谨~, 所以这里用nginx来部署wordpress.
确保安装了PHP,php-fpm,mariadb, 没有安装的话, 参考本文中具体细节部分来进行安装和配置.
新建数据和 wordpress 下载参考上面的方法一, 这里主要介绍使用nginx去解析wordpress源文件.
当前解压后wordpress的绝对路径是:
Bash
source .vimrc
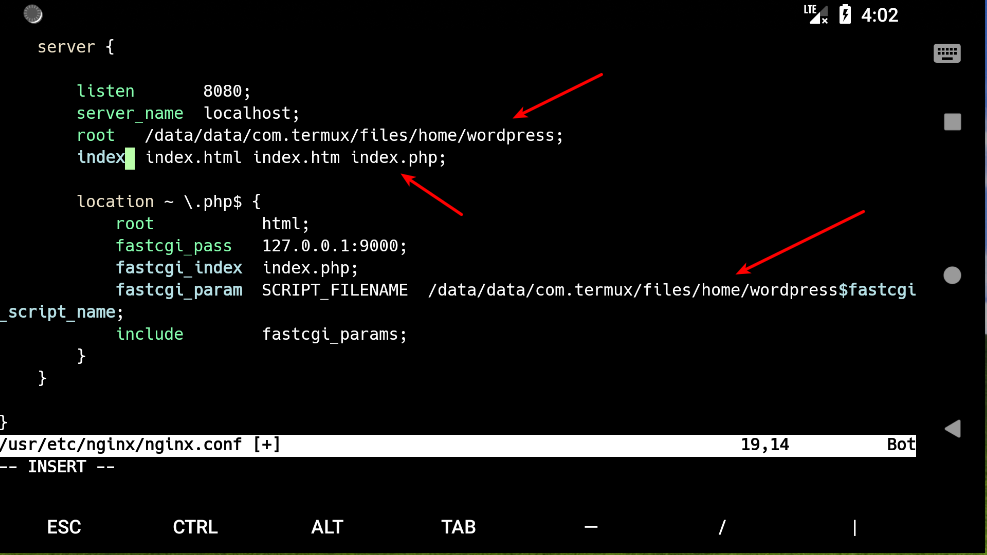
编辑 nginx.conf
Bash
pkg install nodejs
修改为如下几处:
Cannot read property 'length' of undefined
启动 php-fpm 和 nginx
在
proot
环境下面分别启动
php-fpm
和
nginx
, 这里的
nginx
不在
proot
环境下启动后会出一些问题, 感兴趣的可以自己去研究看看.
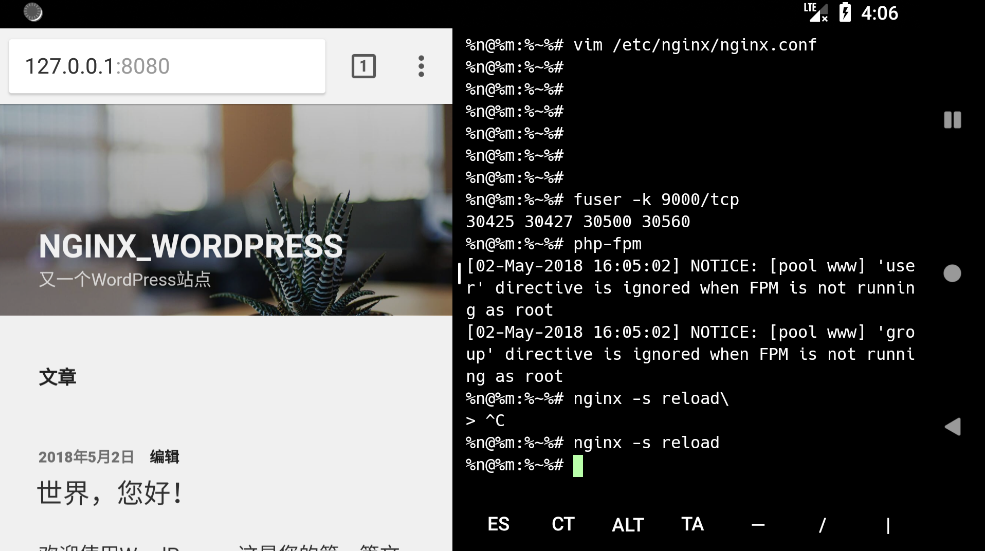
安装 wordpress
浏览器访问:http://127.0.0.1:8080/wp-admin/setup-config.php进行安装.
效果图
同理安装其他博客也就轻而易举了, 可玩性大大增加~
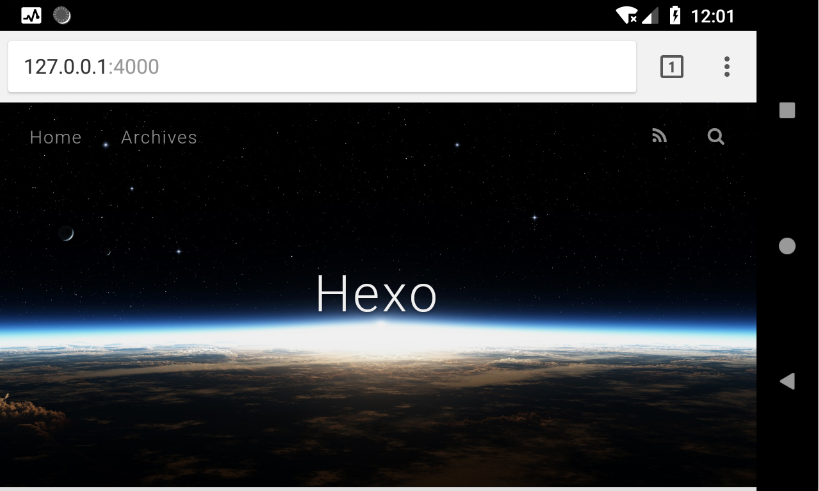
安装 hexo
部署 hexo 博客环境
然后建立一个目录, 然后到这个目录下初始化 hexo 环境
vim $PREFIX/lib/node_modules/npm/node_modules/worker-farm/lib/farm.js
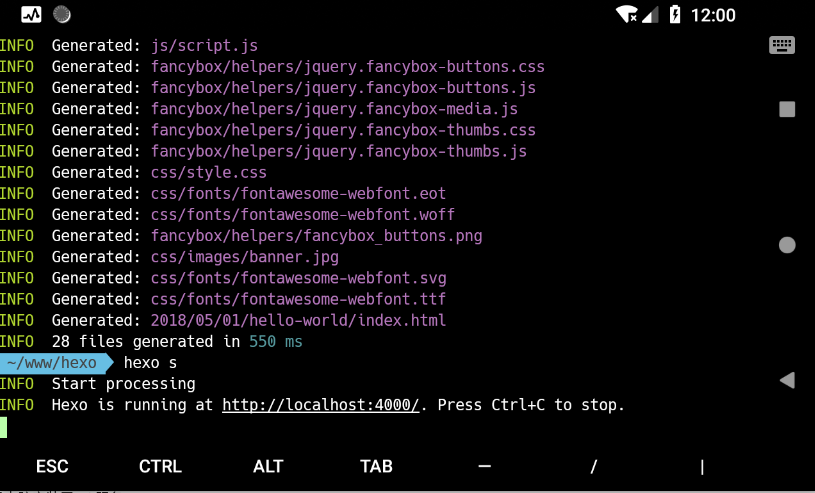
然后就跑起来一个最基本的 hexo 博客
关于 hexo 博客的详细教程, 建议搭建去参考 hexo 官方文档, 我这里重点在于 termux 其他的不作过多的叙述.
效果图
有时候要操作电脑, 这个时候有了termux, 躺在床上就可以操作电脑了, 岂不是美滋滋~~
安装openssh
然后就可以直接 ssh 连接你的电脑了
前提是电脑安装了 ssh 服务
Bash
pkg install mariadb
手机连接操作电脑效果图:
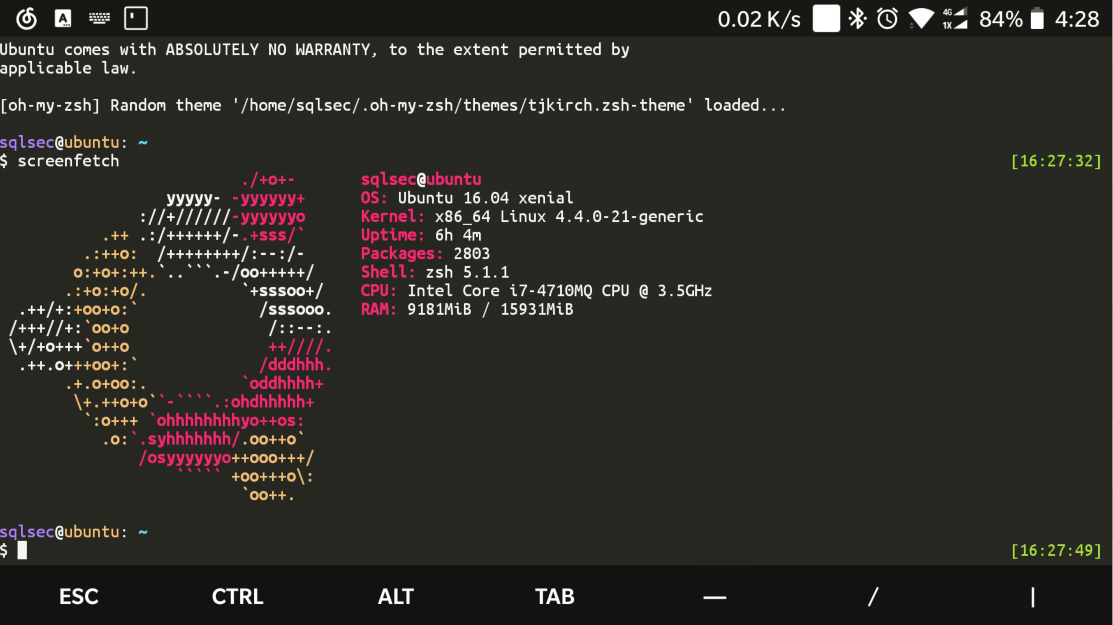
emmm 这个需求比较鸡肋, 但是写文字嘛就得写全了~
安装 openssh
同样也需要openssh才可以
启动 sshd
安装完成后,sshd服务默认没有启动, 所以得手动启动下:
因为手机上面低的端口有安全限制, 所以这里的openssh默认的sshd默认的服务是8022端口上的.
ssh的用户名用whoami命令看下.
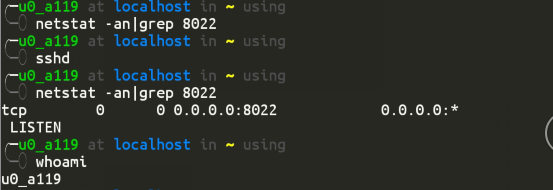
可以看到
sshd
启动后, 端口才可以看到.
PC 端生成公钥
ssh登录是 key 公钥模式登录, 首先在 PC 端生成秘钥:
Bash
mysql_install_db
执行完成后,会在家目录下创建 3 个文件
id_rsa, id_rsa.pub , known_hosts
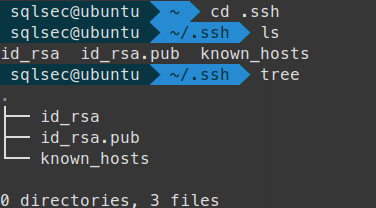
拷贝公钥到手机
然后把公钥id_rsa.pub拷贝到手机的data\data\com.termux\files\home\.ssh文件夹中.
将公钥拷贝到验证文件中
在Termux下操作
Bash
mysqld

PC 端连接手机 termux
Bash
mysql
效果图
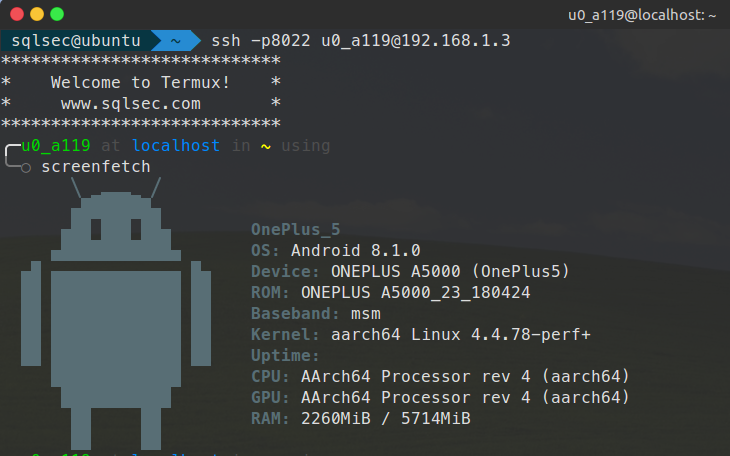
pc 端连接手机 termux 真心鸡肋呀~(忍不住自己吐槽下自己)
Aria2 是一个轻量级多协议和多源命令行下载实用工具。它支持 HTTP / HTTPS, FTP, SFTP, bt 和 Metalink。通过内置 Aria2 可以操作 json - rpc 和 xml - rpc。配置好的话还可以高速下载百度云文件.
安装 aria2
本地启动服务
Bash
mysql_secure_installation
这个rpc服务默认监听的是6800端口, 启动后方便下面的 Web 界面连接操作.
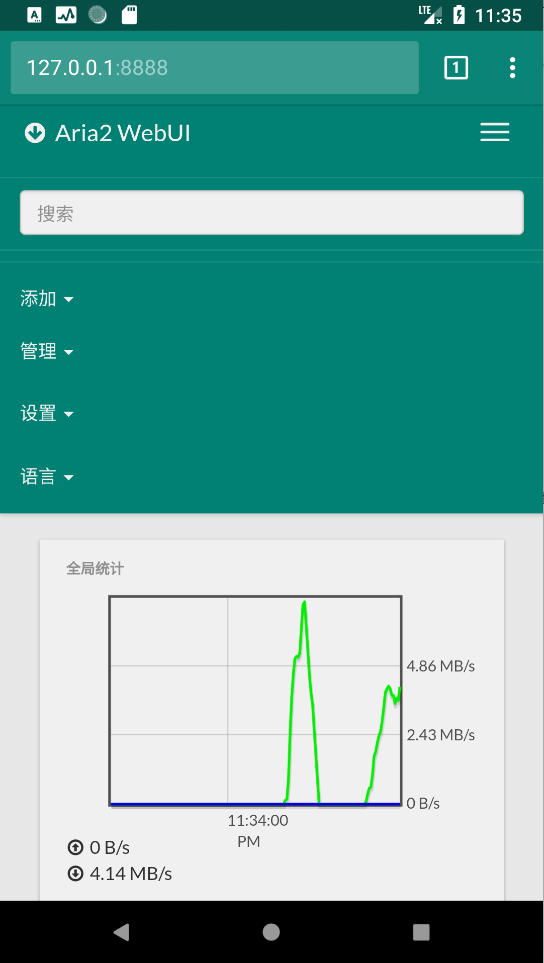
webui-aria2
这是个 Aria2 的热门项目, 把 Aria2 封装在了 Web 平台, 操作起来更加简单便捷。
Enter current password for root (enter for none):
需要 node 来运行, 没有安装的 话使用pkg install nodejs来安装
使用效果图 , 速度蛮快的 , 有兴趣的可以研究如何利用aria2来下载百度云文件, 等你们来探索.
官方项目地址
安装 caddy
官方: 到目前为止,在 Android 上运行 Caddy 有两种方式:Termux和adb, 所以那就顺便折腾一下看看吧:
Bash
Set root password? [Y/n] y
New password:
Re-enter new password:
这一步可能执行要3番钟左右, 耐心等待一下即可.
编写配置文件
内容如下:
Bash
Remove anonymous users? [Y/n] Y #是否移除匿名用户
Disallow root login remotely? [Y/n] n #是否不允许root远程登录
Remove test database and access to it? [Y/n] n #是否移除test数据库
Reload privilege tables now? [Y/n] y #是否重新加载表的权限
这里的8080端口号可以随意指定, 因为手机权限比较低, 所以一般设置1024以上的端口.
注意8080和{之间有一个空格
注意/ / sdcard 两个斜杠之间也有一个空格
启动 caddy
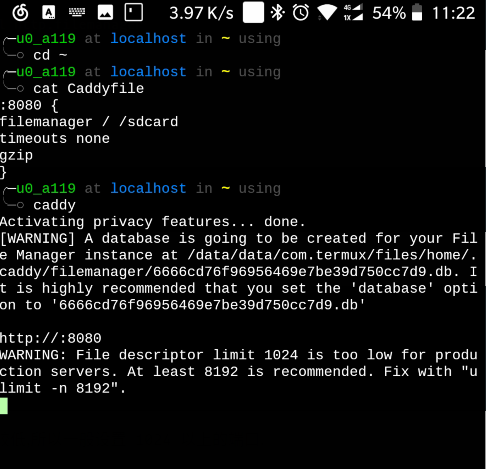
效果
浏览器访问:http://127.0.0.1:8080即可, 局域网内的用户访问手机 ip 地址即可.
默认账号和密码为admin,admin.
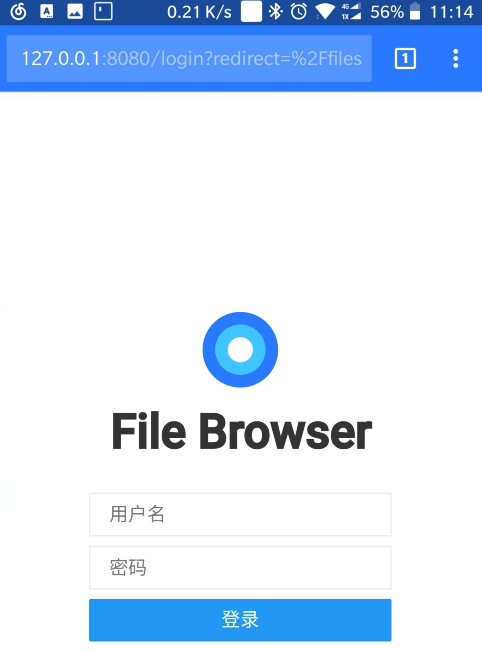
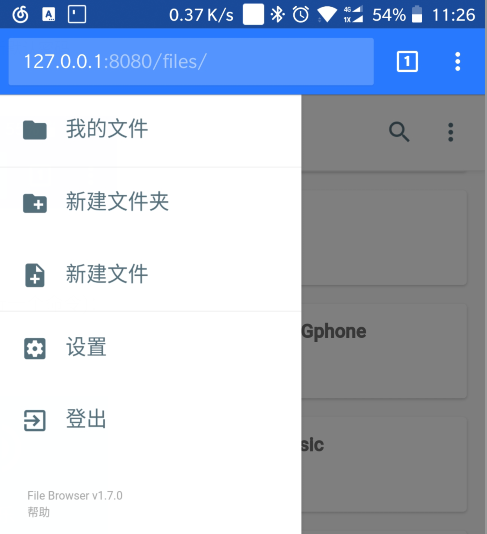
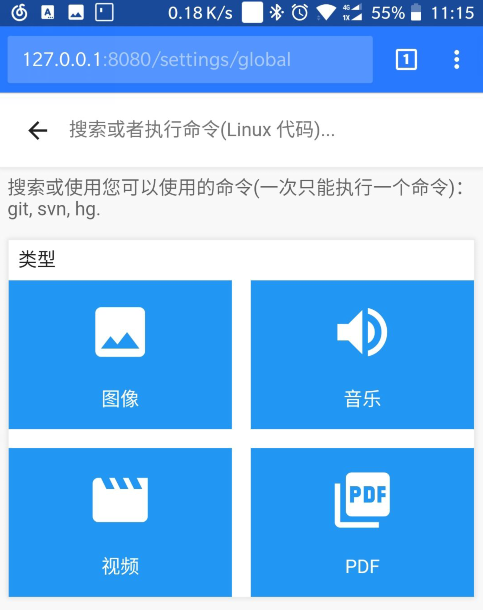
可以在设置界面里面 设置简体中文, 可以修改更新默认密码.
可以直接查看文件, 也支持Linux命令搜索.
Termux:API,用于访问手机硬件, 实现更多的可玩性, 可以实现如下等功能:
- 访问电池信息
- 获取相机设备信息
- 获取本机设备信息
- 获取设置剪贴板信息
- 获取通讯录信息
- 获取设置手机短信
- 拨打号码
- 振动设备
安装 Termux-api
Termux-api Google Play 下载地址
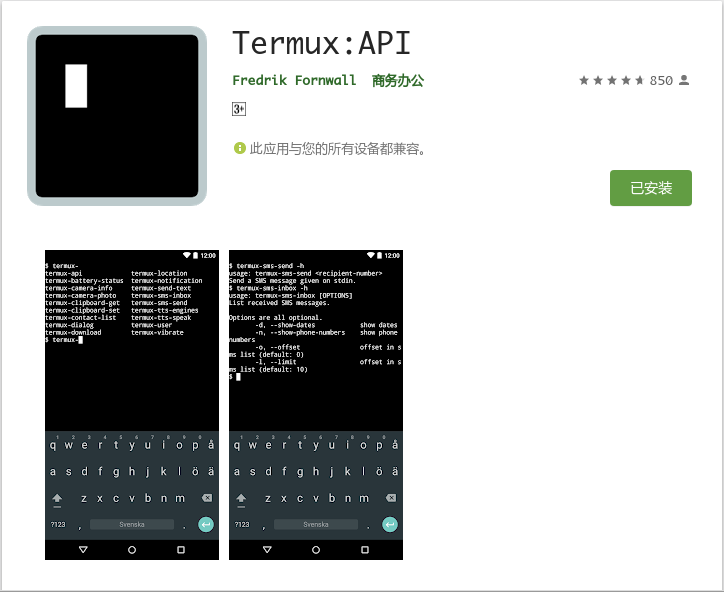
补充一下链接如何在电脑上下载 Google play 上的应用?
安装 Termux-api 软件包
安装完Termux-apiAPP 后,Termux里面必须安装对应的包后才可以实现操作手机底层.
Bash
$ mysql -uroot -p
Enter password: ***apache2
下面只列举一些可能会用到的, 想要获取更多关于Termux-api的话, 那就去参考官方文档.
获取电池信息
Bash
pkg install tmux
可以看到电池的 - 健康状况 - 电量百分比 - 温度情况等
Bash
tmux new -s mysql
获取相机信息
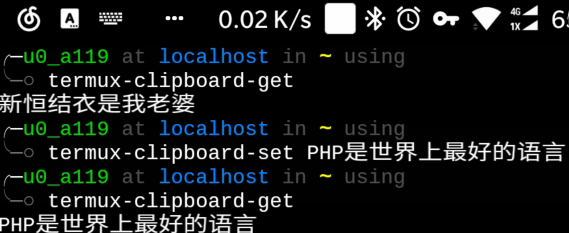
获取与设置剪贴板
查看当前剪贴板内容
设置新的剪贴板内容
mysqld
效果演示
获取通讯录列表
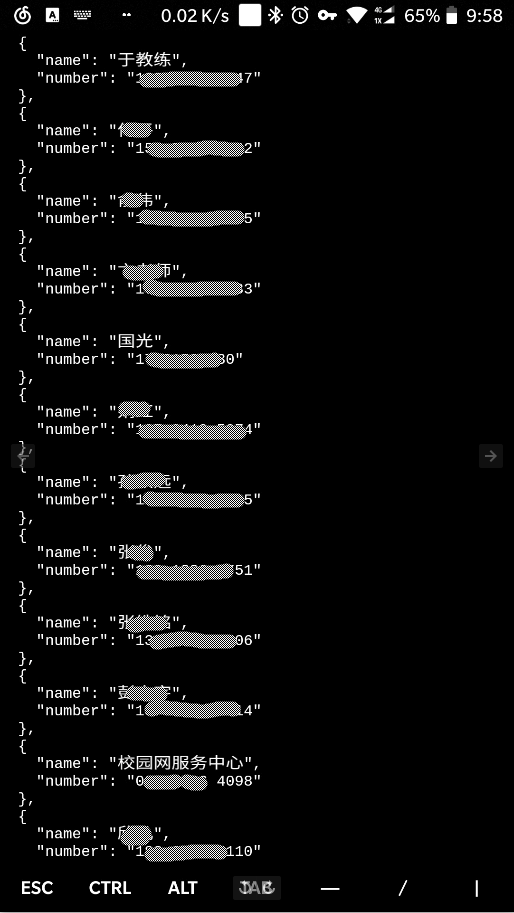
查看短信内容列表

发送短信
支持同时发送多个号码, 实现群发的效果, 官方介绍如下:
mysql -uroot -p
发送测试
Bash
pkg install php

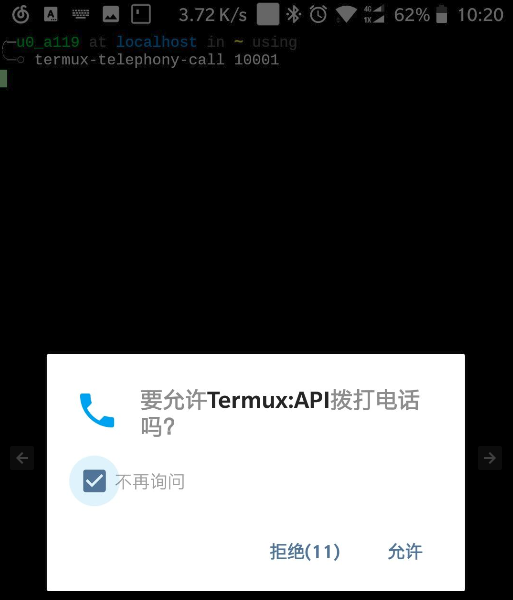
拨打电话
Bash
<?php phpinfo();?>
拨打电话给10001中国电信, 查看下话费有没有欠费~?
php -S 127.0.0.1:8080 -t www/
WiFi 相关
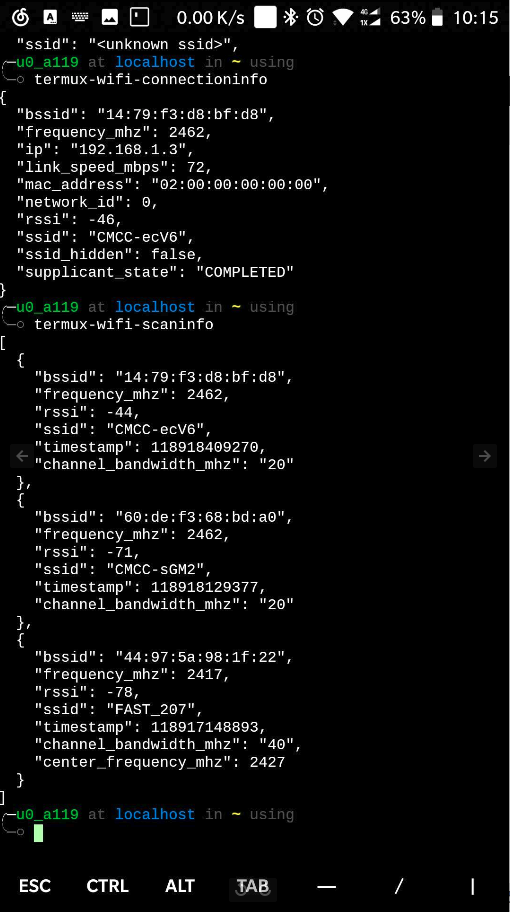
获取当前 WiFi 连接信息
Bash
pkg install nginx
获取最近一次 WiFi 扫描信息
小结
直接操作调动系统底层的话, 可以通过编程来实现自动定时短信发送, 语音播报等 DIY 空间无线
一些无聊有趣的版块, 如果你是一个正经讲究人, 可以跳过这个板块以节约你的阅读时间.
nyancat 彩虹猫
彩虹貓(英语:Nyan Cat)是在 2011 年 4 月上传在 Youtube 的视频,并且迅速爆红于网络,並在 2011 年 YouTube 浏览量最高的视频中排名第五.
Bash
termux-chroot
什么鬼完全 Get 不到国外人的趣味点
终端二维码
Linux 命令行下的二维码, 主要核心是这个网址:http://qrenco.de/
Bash
nginx
如果你不嫌无聊的话还可以扫描这个二维码, 然后就打开我的博客了.
终端地图
一个基于nodejs编写的命令行下的地图.
netstat -an |grep 8080
进入终端地图
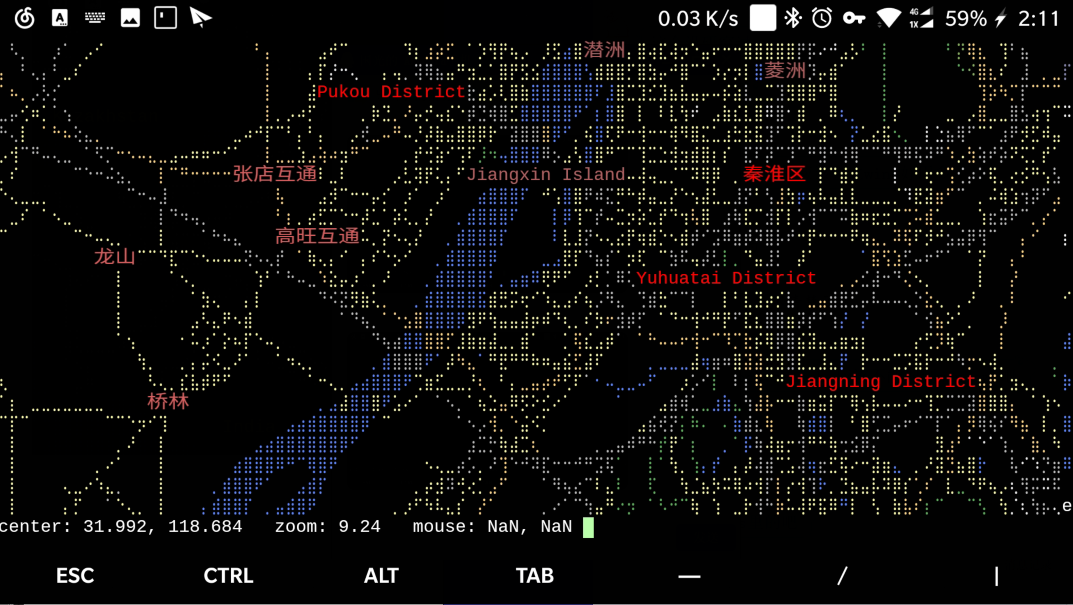
操作方法
终端下的地图! 讲究人~ 如果你足够无聊的话, 还可以尝试能不能在这个地图上找到自己所在的位置.
安装 Linux
甚至还可以在Termux里面在安装其他的Linux发行版.
由于本文篇幅已经过长了, 这里不在叙述了, 感兴趣, 能折腾的自己去找一些资料. 下面列出目前网友们用Termux可以成功安装的发行版:
- Ubuntu
- Arch
- Fedora
- Kali Nethunter
Ubuntu
Fedora
内网穿透
使用ngrok或者frp可以将Termux上面搭建的网站映射到外网上去,手机建站也不是不可能了.
Python Jupyter Notebook
Jupyter notebook(又称 IPython notebook),支持运行超过 40 种编程语言。Python 的一个强大的模块, 成功安装的话可以实现比caddy的效果, 支持web下的终端操作, 支持代码高亮运行. 由于这里需要安装大量文件, 加上用户需求比较少, 这一块感兴趣的话可以自己去探索.

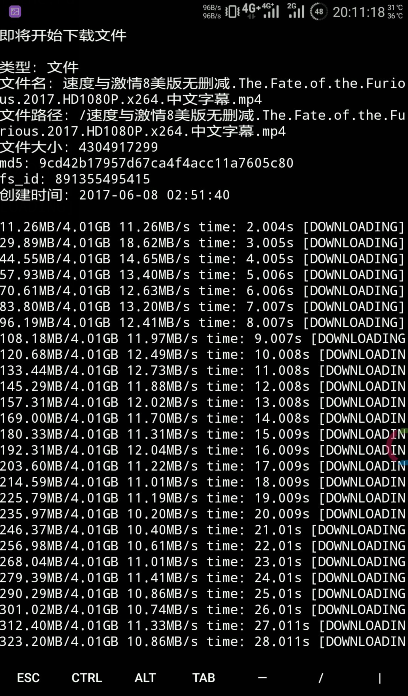
下载工具
是一款命令行工具,用来下载网页中的视频、音频、图片,支持众多网站,包含 41 家国内主流视频、音乐网站,如 网易云音乐、AB
站、百度贴吧、斗鱼、熊猫、爱奇艺、凤凰视频、酷狗音乐、乐视、荔枝 FM、秒拍、腾讯视频、优酷土豆、央视网、芒果 TV
等等,只需一个命令就能直接下载视频、音频以及图片回来,并且可以自动合并视频。而对于有弹幕的网站,比如 B 站,还可以将弹幕下载回来
仿 Linux shell 文件处理命令的百度网盘命令行客户端.
项目地址
可以完美在Termux上运行.
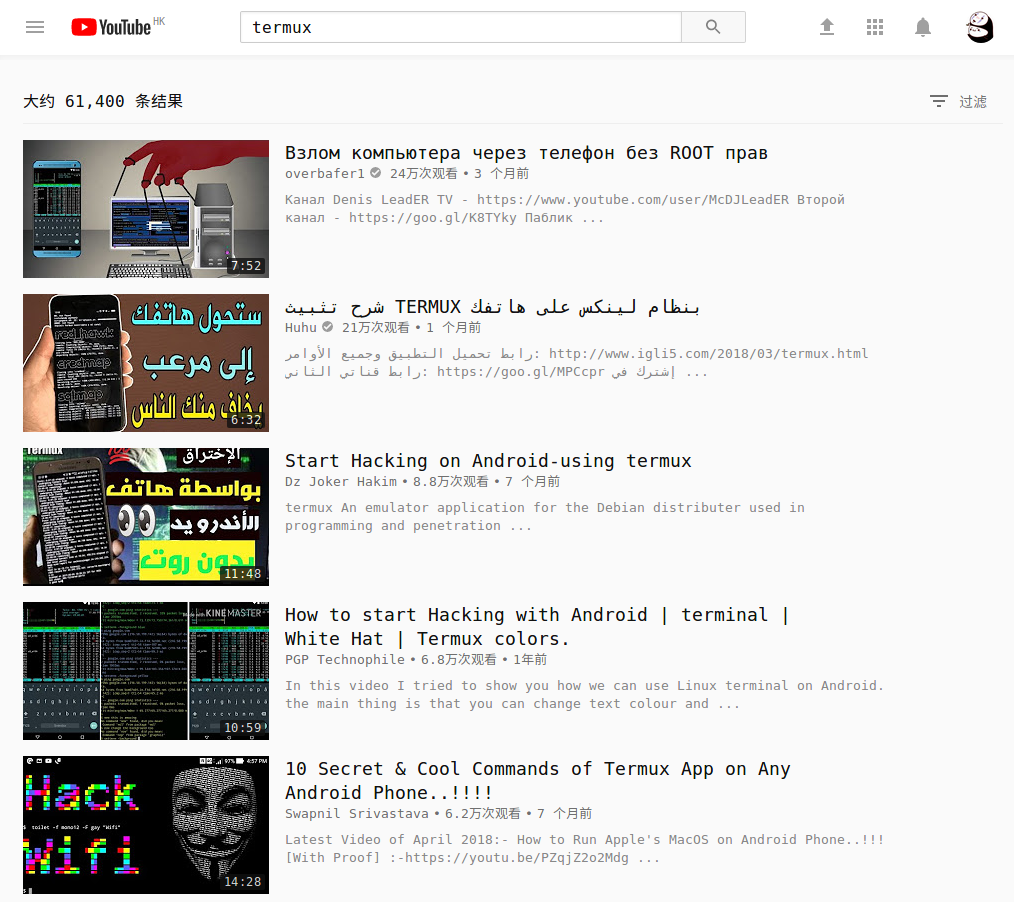
相对来说 国外的 Termux DIY 的氛围比国内好很多, Youtube 上的视频都有很高的播放量:
当然国内也有这么一批执着于Termux的玩家, 只是相对来说还比较小众, 写这篇文章只想让更多的人认识到Termux的生产力, 使用Termux来做一些很 cool 的事情. 期待有更多Termux的优秀文章出现~